What is AI Video Generation? How Text-to-Video AI Works in 2026
A comprehensive technical explainer on how AI video generation works, from diffusion models and transformer architectures to the practical systems powering tools like Seedance 2.0. Understand the science behind text-to-video AI.
AI just learned to make movies. Type a sentence, wait a few seconds, and a model like Seedance 2.0 hands you a cinema-grade clip with synchronized audio. Here is how that actually works — and why it matters for anyone creating video in 2026.
TL;DR
- AI video generation turns text prompts (or a photo) into moving video, usually 4 to 15 seconds long.
- It works by using diffusion models that start from random noise and progressively refine it into coherent frames guided by your words.
- In four years the technology has gone from blurry 2-second clips to 720p cinematic footage with native audio — and it keeps getting faster and cheaper.
- You can start for free at seedance.it.com with 50 credits on signup.
What AI Video Generation Actually Is
Think of AI video generation as a text-to-video translator. You describe what you want to see — "a red fox darting through fresh snow at sunrise, shallow depth of field" — and a trained neural network produces the video.
The model was not given that specific scene during training. It learned general visual concepts (foxes, snow, morning light, shallow focus) from billions of video frames and now composes them on demand. It is not editing stock footage. Every pixel is generated.
Two main input modes exist today:
- Text-to-video: a written prompt becomes a full video clip.
- Image-to-video: you supply a starting image and the model animates it with motion you describe.
Modern platforms like Seedance 2.0 support both. Earlier tools such as Seedance 1.0 Lite and Pro specialize in image-to-video, which is cheaper and gives you tight control over the opening frame.
Skip the theory — generate one
The fastest way to understand AI video is to make one. 50 free credits, no card, first clip in 5 minutes.
Try Seedance 2.0 FreeThe Science in Plain English: Diffusion Models
Here is the core trick behind every serious AI video model today.
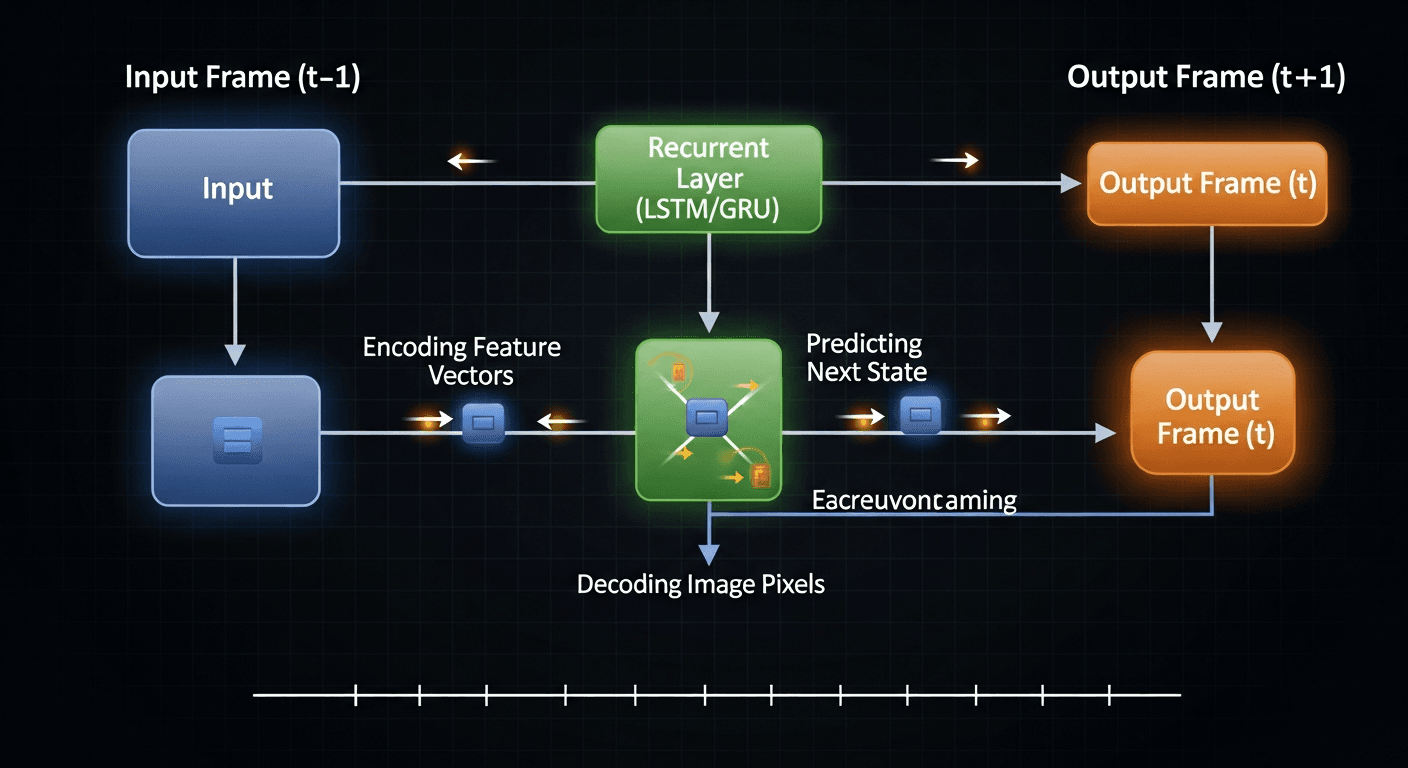
Imagine a clean photograph. Now imagine slowly covering it in TV static — layer after layer — until the image is pure noise. A diffusion model is trained to reverse that process. Given pure noise, it learns to subtract the static one step at a time until a coherent image emerges.
Key insight: the model never memorizes videos. It learns the process of turning noise into meaningful pictures that match a text description.
For video, the same idea extends into time. Instead of denoising a single frame, the model denoises a stack of frames at once — and it has to make sure the fox in frame 47 looks like the same fox in frame 48. That temporal consistency is the hardest problem in the field, and it is where the top models pull ahead.
Why transformers matter
The other half of the puzzle is the transformer architecture — the same family of networks that powers large language models. Transformers use an "attention" mechanism that lets the model weigh relationships between all parts of a scene at once:
- Spatial attention keeps objects in sensible places within a frame.
- Temporal attention keeps them behaving consistently across frames.
- Cross-attention links your text prompt to what the model generates at every denoising step.
Modern systems called Diffusion Transformers (DiTs) combine both techniques. ByteDance's Seedance and Seedream models are built on this approach, which is why they scale so well as training data grows.
From Blurry Demos to Cinema-Grade: A 4-Year Timeline
| Era | Year | Capability | |---|---|---| | GAN experiments | 2018-2021 | 2-second clips, 256px, heavy artifacts | | First diffusion demos | 2022 | Short, low-res, inconsistent motion | | The Sora moment | 2024 | Minute-long clips at research scale | | Consumer breakout | 2025 | 5-10 second clips, usable quality | | Cinema-grade era | 2026 | 720p, 15s, native audio, $3 per clip |
Four years ago, AI video looked like a melting nightmare. Today, Seedance 2.0 produces 720p footage with synchronized audio that regularly fools casual viewers. The pace of improvement has been roughly 10x per year on quality metrics.

Want to see diffusion models in action? You're 30 seconds away from your first generation. Try Seedance 2.0 free →
What You Can Actually Do With It Today
Theory is nice. Here is what real creators ship with AI video in 2026.
Social media content. A 10-second product reveal for TikTok, Reels, or Shorts. Generation cost: about $3. Traditional production cost for equivalent quality: $500 to $5,000.
Ad creative at scale. Instead of one hero ad, marketing teams generate 40 variations to test against audience segments. Seedance 2.0's native audio sync means no separate sound design pass.
Storyboards and previz. Directors use AI video to visualize shots before committing to production — faster and cheaper than traditional animatics.
Explainer videos. Pair Seedance visuals with OmniHuman v1.5 for a talking presenter and you have complete explainer content in an afternoon.
Music video cuts. Individual shots in music videos typically run 2 to 8 seconds — right in Seedance 2.0's sweet spot.
Product imagery that moves. Generate a still with Seedream v5, then animate it. Two stages of creative control, about $3.10 total.
The Three Numbers That Define Quality
When you compare AI video tools, three specs matter most:
- Resolution — Seedance 2.0 ships at 720p, which is ideal for social and web. 1080p models exist but burn significantly more compute per frame.
- Frame rate — almost all serious models generate at 24fps, the cinema standard. Anything lower feels stuttery; higher rarely helps.
- Duration — 4 to 15 seconds is the current practical ceiling for most models. Longer videos accumulate tiny inconsistencies that add up to drift.
For a deeper dive, read our guide on AI video quality explained.
The Audio Breakthrough
Until 2025, almost every AI video tool produced silent clips. You had to composite sound effects and music in post — a tedious step that broke the magic.
Seedance 2.0 generates audio and video together. A beach scene produces wave sounds. A city street gets traffic noise. Footsteps land on the correct frame. This single feature eliminates hours of post-production for most creators.
Experience native audio for yourself
Most AI models hand you silent clips. Seedance 2.0 delivers synced audio out of the box. Try it on the house.
Generate With AudioWhere to Start (Without Spending a Dollar)
The fastest way to understand AI video is to generate one. Here is the no-cost path:
- Sign up at seedance.it.com. You get 50 free credits — no subscription, no credit card.
- Pick a model based on your goal. Seedance 2.0 for flagship quality, Seedance 1.0 Lite for cheap experimentation.
- Write a specific prompt. "Cinematic shot of rain hitting neon puddles in Tokyo at night, slow push-in, shallow depth of field" beats "rainy city."
- Review, iterate, and refine. Small prompt changes produce meaningfully different output.
When you outgrow the free tier, Seedance uses pay-as-you-go credit packs starting at $10. No monthly commitment, no seat fees.
The Bigger Picture
AI video generation in 2026 is where photography was in 1850: technically impressive, obviously useful, and about to reshape several industries. The cost curve is brutal. A clip that cost $200 to produce in 2023 now costs $3. By 2027 it will be cents.
The creators who will benefit most are the ones who start building fluency now — while the competitive advantage is still "uses this well" rather than "uses this at all." For predictions on where the field heads next, read our 2026-2027 forecast.
The technology is here. The tools are free to try. The only remaining question is what you will make with them.
Ready to create your first AI video? Start free with Seedance 2.0 → — 50 credits on signup, no card required.